End-to-end encryption for a web document editor
Blueprint for an end-to-end encryption of a web document editor.
Intro#
I am working on a side project that helps to deal with information overload, it's name is "Mazed". I'll talk about the project separately, as for now I would like to talk about data storage and privacy in it.
Mazed has to store a lot of potentially sensitive data remotely, which instantly raises the issue of trust to the infrastructure and service maintainers. Service can claim to not use personal data commercially and protect privacy very carefully by investing millions to security, but there is always a place for a mistake or government request that can not be ignored. Therefore even reliable infrastructure and reputation of a company can not guarantee that your private sensitive information is not read by other people without your permission. End-to-end encryption in such cases is a good solution, where privacy could be guaranteed by system design. This technique is already used in existing systems, like Signal, WhatsApp. I have tried to apply the same principles to "Mazed".
Object#
This is a simple document editing web application written in React on JS. A document is owned and edited by a single user - no sharing. All documents are stored remotely on a server side and are available via API. Documents are searchable by fuzzy text search.
Objectives#
Eliminate any realistic possibility to read and understand documents content:
- by remote server owners,
- by local non-authorised users.
Tenets#
- User's privacy is a top priority.
- User experience, as always, must be simple and straightforward.
💡 Assumptions#
There are some assumptions that I used in suggested solution:
- The remote server can not be trusted. Even if a service has perfectly secure infrastructure, which hardly ever takes place, people can not be trusted. We are curious, emotional, we can be bribed or blackmailed, we make mistakes, lots of them. This is human nature.
- Any local storage is not secure either. A local machine could be compromised easily, it happens all the time. It is not trusted, unless a user is authorised, at least by password.
- There are only standard storage solutions available locally: cookies, local storage, etc.
- There are secure enough encryption functions available. The cost of brute forcing or hacking the cipher is high enough to make it unprofitable for a single user.
- A user can store and transfer a secret key between devices securely. For instance there are plenty of handy solutions available to assist in it, like 1password or LastPass, etc.
- JS is a good enough option for this project. It is clearly not the best one for security and performance reasons, but it is still good enough for the first version of the editor to verify other assumptions and the idea as a whole. Later Web Crypto API must be used.
- The meta information for the search is notably smaller than a document itself.
- Latest documents should be prioritised over early ones in search results.
- Part of the document's meta information can be opened to a remote server:
last update date,creation date,document id,local secret id.
Requirements#
- It should be guaranteed by design that remote service can not read (decrypt) document content or it's parameters, such as type, title etc.
- A locally stored information should be protected from unauthorised users.
- An encrypted data should be properly signed to make sure that data is not altered.
- Solution should support text search of documents.
❓ Problems & gaps#
- How to store a local secret securely to prevent it from being compromised?
- How to support fast enough fuzzy search over documents without disclosing any sensitive data to the server?
- How to change local on multiple devices?
📜 Solution#
An encryption and crypto signature would be the most straightforward and good enough solution here. A document could be encrypted and signed locally with a local secret key, therefore remote service would get only encrypted blobs of data and secret ID.
encryptAndSign(Document, Secret) -> EncryptedDatastoreRemotely(Id, EncryptedData)getRemotely(Id) -> EncryptedDatadecrypt(EncryptedData, Secret) -> Document
🏗 Key decisions#
There are 3 issues with this approach as I mentioned in the "problems & gaps" section.
🔐 Keep the local secret#
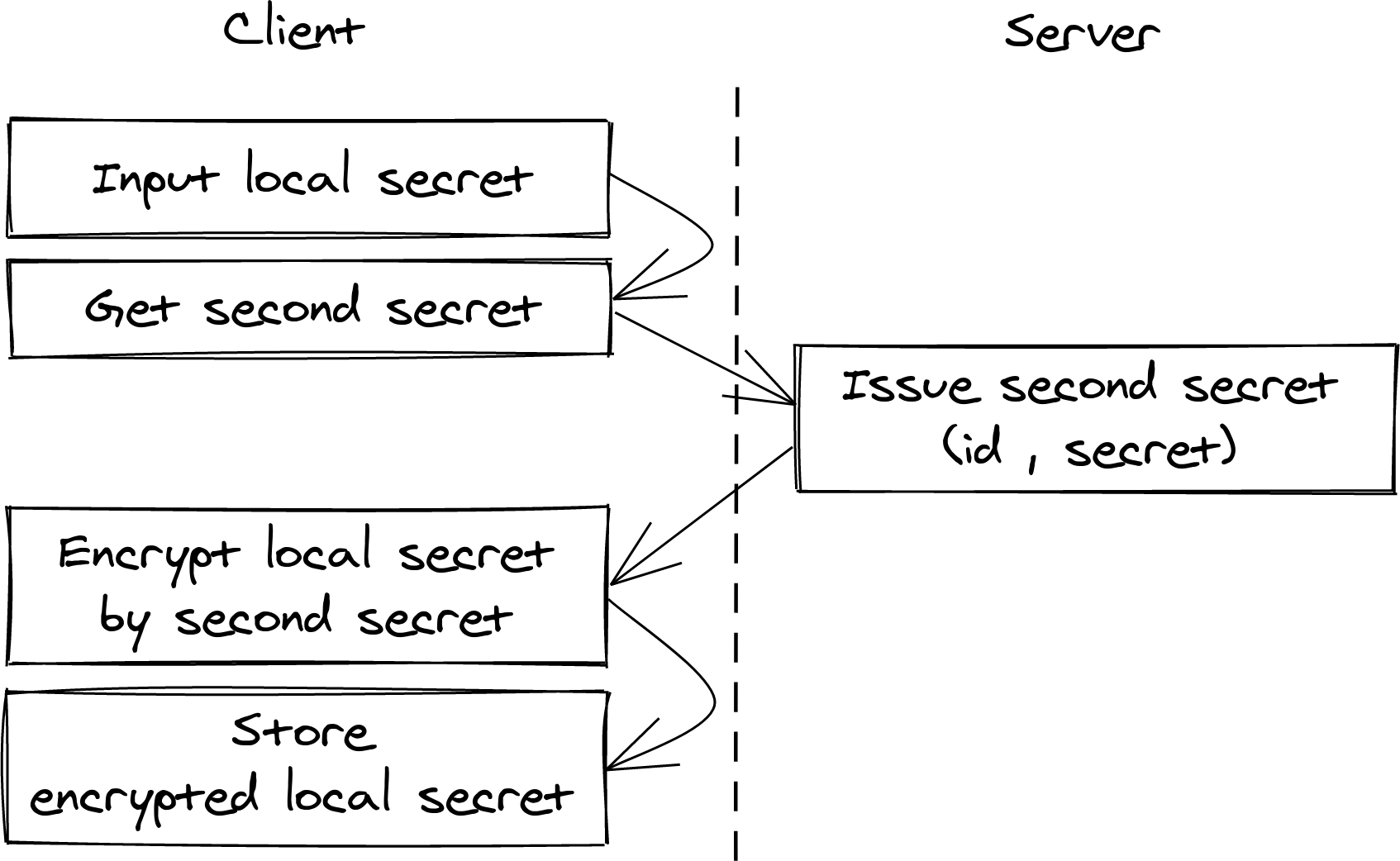
First of all we have to preserve and protect a local secret between sessions to avoid the tedious routine of adding the secret every time when a user opens the editor. We do have a non secure local storage, so the secret must be encrypted. But we need another secret for that - "second secret". We can not afford to ask a user to input one more secret every time when the editor is opened, it would increase a user facing complexity of the system. Complexity of system security always leads to security breaches: human mistakes, weak passphrases, secret leaks. Because it's too much to make a user remember all the passwords, codes, security phrases and secret questions. Normally they barely understand when and how to use them, what should be kept private. Instead let's issue a second secret remotely and provide it on demand to the editor. So algorithm of adding and encrypting local secret looks like that:
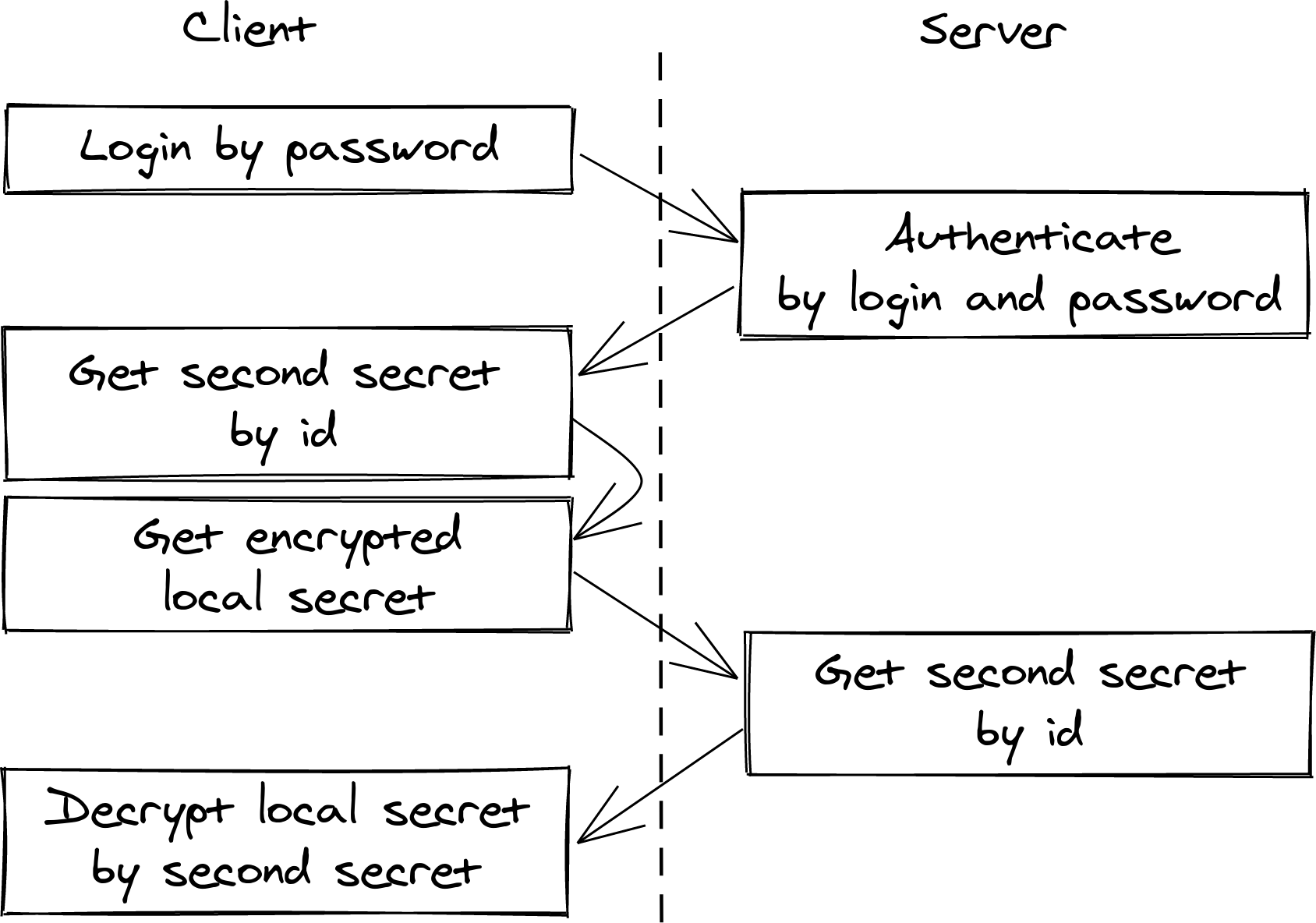
Algorithm of session activation looks like that:
From user perspective it would require 2 types of input:
- First login on device: login, password, local secret.
- All other logins only take a password to login to the remote server and get the second secret to decrypt the local one.
🔎 Search encrypted documents#
Secondly, we have to support fuzzy search over documents without disclosing any information about content to the remote server. It's not possible remotely, due to restrictions - let's do it locally then.
Let's use an assumption, that latest documents should be prioritised above old ones in search results. If a document's encrypted search meta-information is smaller than the document itself, we can request this information chunk by chunk starting from the latest updated documents. The size of each chunk varies depending on network and client memory restrictions. (A single web page that takes more than a few hundred MiB of memory is surely ridiculous, even today). Then we search for a pattern in each chunk, showing matched ones to a user, until the screen is filled. On scroll down the process will be continued. Therefore the search can be performed on a local machine only.
A search for very old documents in a big number of them is certainly a problem here, we would need to download all meta-information on each search session. That would be a heavy burden for big document sets and poor network connection. But there is a useful benefit of receiving documents sorted by update date. Metadata of documents older than some certain time could easily be cached to local storage. Hence only the first chunk with latest updated documents could be received for every search, older documents are already in the cache - no need to download them again. Criteria of cache invalidation is quite simple, when a document appears in the first chunk, it should be removed from the cache. That means it was updated recently.
In this case a maximum size of meta information for a document is 7KiB. So for a corpus of documents of size 10'000 it would be 7MiB of cache size, which is good enough to store in memory. Also it is not too big for a local storage, if you want to share it among different sessions.
I will talk about the search algorithm in another time, just to keep this one short.
♻ Replace local secret#
From time to time there is a need to replace the existing local secret with a new one, because for instance the old one was leaked. All encrypted documents have to be re-encrypted with a new local secret. Also the local secret should be replaced at the same time on multiple devices with no interruption of regular workflow.
This could be solved in multiple ways, I have chosen the one with coexisting of 2 local secrets for the time of migration.
For the simplicity of explanation let's say we perform a re-encryption on only 1 device, let's call it "migrator" (it could be the one with the stable network connection and some spare memory and CPU time).
To replace local secrets the new secret has to be generated and added to "migrator", where the old one is marked as deprecated. Before starting the migration new local secret should also be added to all devices the work of documents reading and writing should be continued during the migration. It would certainly be too much to ask from a user to avoid deleting the old local secret or using it, until the migration is finished. Clients can control it, using the information about the local secret stored in the server. There are 4 stages of local secret:
- Active
- Deprecated, but still some documents are encrypted by it. Server would reject a new document encrypted by it.
- Deprecated, ready to be removed
The migration itself is a simple 4 step routine:
- Download each document,
- decrypt it with the old local secret,
- encrypt it with the new local secret,
- submit it to the server.
Migration process could be stopped at any moment and resumed later, as far as none of new submitted documents are encrypted with the old local secret.
🏁 As a close#
Privacy is one of the most important problems these days, if we don't want our personal emails, documents, photos, messages to be sold from company to company for an unknown reason. There is no such thing as complete anonymisation. There are lots of ways to figure out who a certain message belongs to, as far as some meta information provided along with it. This is matter for another post, here I just want to mention, that with awareness of our own privacy we better choose software with privacy guaranteed by design. Such as end-to-end encryption, that was described here.
I do understand that the suggested algorithm is simple, perhaps too simple to be used as it is. But as any practical solution it should be implemented, used and improved incrementally. Where every improvement is dictated by verified and more importantly refuted assumptions, according to the well known "tracer bullets" approach, suggested by Andrew Hunt and David Thomas in The Pragmatic Programmer (highly recommend).
Should you have any questions, concerns, suggestions please do not hesitate to drop me a line, I'm always happy to hear from you.